Decision Trees — Hyperparameters
As we have discussed in the previous session about Decision Trees, so moving forward today we will discuss Decision tree Hyperparameters.

Why Hyperparameters is needed in Decision Tree?
Decision trees make very few assumptions about the training data. If left unconstrained, the tree structure will adapt itself to the training data, fitting it very closely-indeed, most likely overfitting it. Such a model is often called a nonparametric model, not because it does not have any parameters but because the number of parameters is not determined before training.
In contrast, a parametric model has some degree of freedom so to reduce the risk of overfitting and underfitting.
Hyperparameters for Decision trees
1) Criterion
criterion{“gini”, “entropy”, “log_loss”}, default=”gini”
The function to measure the quality of a split.
So should you use Gini Impurity or entropy? The Truth is, most of the time it does not make a big difference. they lead to similar trees. Gini impurity is slightly faster to isolate the most frequent class in its own branch of the tree, while entropy tends to produce slightly more balanced trees.
2) Depth Of Tree
To avoid overfitting the training data, you need to restrict the Decision tree’s freedom during training. In scikit-learn, this is controlled by the max-depth hyperparameter (the default value is none which means unlimited ).
Reducing max_depth will regularize the model and thus reduce the risk of overfitting.

In the above two pictures, you can see that the model in which the max_depth = None(which means unlimited) extracted all the nodes where it cant be further divided and in the second case we limited the max_Depth with value 3, which means it will stop dividing the nodes after 3rd node.
And you can also see the difference in accuracy where in one where max_depth=None the accuracy is 87% and max_Depth=3 accuracy is 92%.
The difference in accuracy is because where max_depth=None it extracted all the nodes there is a large possibility that some nodes(datapoints) would be noise/Outliers/Erroneous, which makes our algorithm more prone to overfitting. But if you take the max_depth value too low then it can also cause underfitting so you have to find the sweet spot and the way of finding the sweet spot is to experiment with max_depth values.
I hope I have made you clear about the max_depth parameter and you don’t have confusion as this is the most important parameter of the Decision tree if I failed to explain it please write your comment so that I can later improve this article.
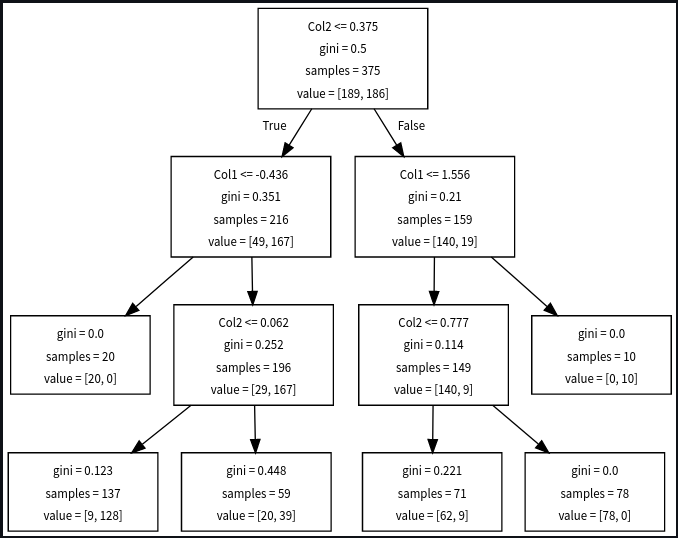
3) Min Sample Split
It basically means that the number of samples a node must have before it can be split further.

you can see in the above picture that the last node where the sample is 72 and 65 is not further split because we set the parameter min_sample_split = 100, which means to split the nodes if that node contains more than 100 samples.
The general idea is the more you put the value in min_sample_split the more it is prone to underfitting and if you reduce the value very much there is more chance of overfitting.
4) Min Sample Leaf
It means the minimum number of samples a leaf node must have.

you can see in the above picture that the last node where the sample is 115 and 101 is not further split because it is about that if these two nodes get to split the leaf node of that 2 nodes will contain less than 100 samples so it does not split further.
min_sample_split and min_sample_leaf are more or less the same
The more you put the value in min_sample_leaf the more it is prone to underfitting and if you reduce the value very much there is more chance of overfitting.
5) Max Features
By this hyperparameter you can control how many columns should be given to your decision tree algorithm.
Ex: If you have a data set of 100 columns and in your decision tree algorithm you apply hyperparameter max_depth=50. The algorithm for finding the information gain is not in the original 100 columns but in 50 columns because you set the value to 50, so how will that 50 columns be decided? The 50 columns will be randomly chosen from the 100 columns.
This is how this max feature hyperparameter works and it is used when your model gets overfitted so you reduce the number of columns from which information-gain will be extracted.
6) Max Leaf Node
This helps you to control how much max leaf node will be created after splitting.

Grow a tree with max_leaf_nodes in best-first fashion. Best nodes are defined as relative reduction in impurity. If None then unlimited number of leaf nodes.
7) Min Impurity Decrease
A node will be split if this split induces a decrease of the impurity greater than or equal to this value.
The weighted impurity decrease equation is the following:
N_t / N * (impurity - N_t_R / N_t * right_impurity
- N_t_L / N_t * left_impurity)
Conclusion
I have created a Web app Where you can experiment with this all Hyperparameters and can understand Decision Trees in a better way.

The Link of the web app: GitHub
Follow Me
If you find the ideas I share with you interesting, please don’t hesitate to connect here on Medium, Twitter, GitHub, LinkedIn or Kaggle.
