Anime Recommendation System | Collaborative Method
Introduction

What is Recommendation Systems
Recommender systems are the systems that are designed to recommend things to the user based on many different factors. These systems predict the most likely product that the users are most likely to purchase and are of interest to. Companies like Netflix, Amazon, etc. use recommender systems to help their users to identify the correct product or movies for them.
The recommender system deals with a large volume of information present by filtering the most important information based on the data provided by a user and other factors that take care of the user’s preference and interest. It finds out the match between user and item and imputes the similarities between users and items for recommendation.
Collaborative filtering systems use the actions of users to recommend other movies. In general, they can either be user-based or item-based. Item based approach is usually preferred over user-based approach. User-based approach is often harder to scale because of the dynamic nature of users, whereas items usually don’t change much, and item based approach often can be computed offline and served without constantly re-training.
Analyzing and Preprocessing The Dateset
I will now merge the rating data and anime_contact_data(data extracted from anime_data) in terms of anime_id.


If you see The Data Carefully there are many users who have only voted few anime series and some anime series how have very few votes and i think this can misleading our model. we will take only that data in which a particular anime has more than 200Votes and if a user has gave in total more than 500Votes to the anime.

We will now create a pivot table based on Name and User_id column and save it into a variable name piviot_table

Now we can move to make a model for our recommendation system.
Model Creation
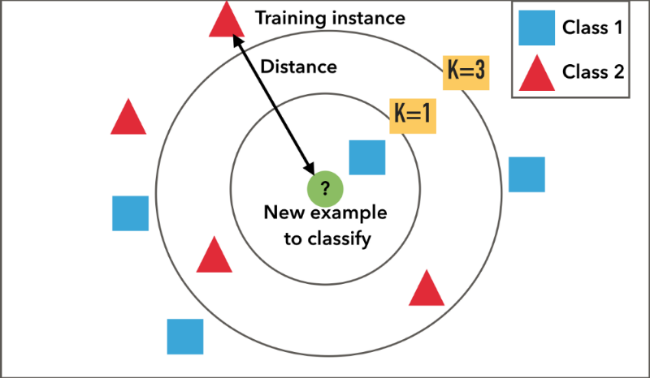
Implementing KNN
We convert our table to a 2D matrix, and fill the missing values with zeros (since we will calculate distances between rating vectors). We then transform the values(ratings) of the matrix dataframe into a scipy sparse matrix for more efficient calculations.
Finding the Nearest Neighbors
We use unsupervised algorithms with sklearn.neighbors. The algorithm we use to compute the nearest neighbors is brute, and we specify metric=cosine so that the algorithm will calculate the cosine similarity between rating vectors. Finally, we fit the model.
Test our model and make some recommendations:
The KNN algorithm measures distance to determine the closeness of instances. It then classifies an instance by finding its nearest neighbors, and picks the most popular class among the neighbors.

I will create a Predict() function so that every time I call this function it will recommend me the 5 most closest recommendations.

RESULT

Outgo and Resources for further Experiment.
If you Liked This Article and you have some doubt and you want the Brief Explanation then please Consider Checking My Kaggle Page where i have discussed this Topic in a brief way and if you want the Source Code for this Project Please Visit my GitHub Repository. I also hosted This project as an Web App the link you will get in my GitHub repository .
Video Demo Of the Web App

